
Posted on October 25, 2023 by Admin
The World’s Most Popular Databases: A Comprehensive List
Introduction
Databases are the backbone of modern information management, powering everything from websites and mobile apps to complex data analytics. With the ever-increasing need for data storage and retrieval, a variety of databases have emerged over the years. In this article, we will explore the world’s most popular databases, each with its unique features, use cases, and advantages.
- Relational Databases:
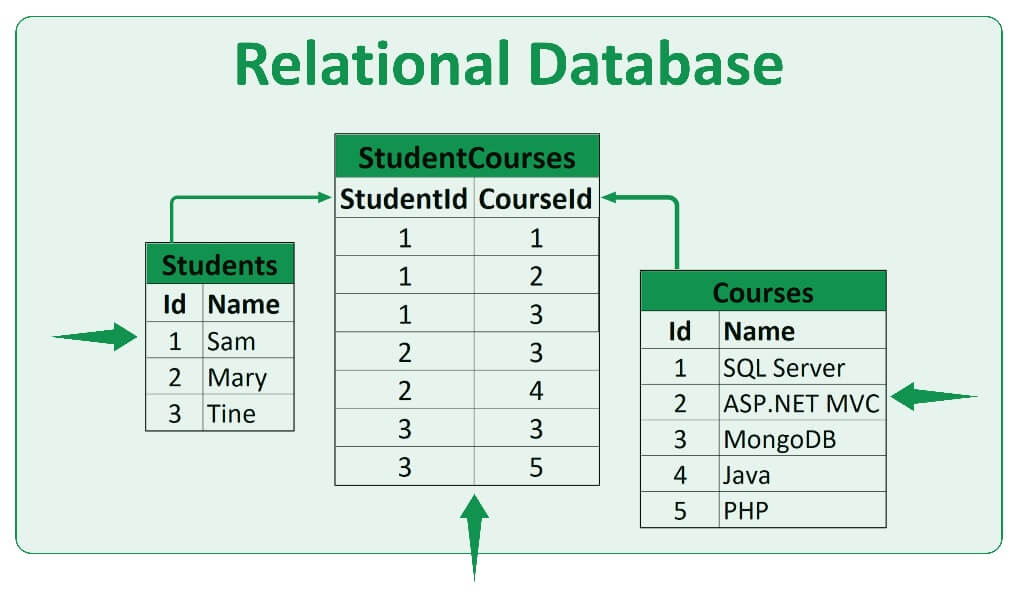
Relational databases are a fundamental category of database management systems (DBMS) that organize data into structured tables and use a system of rows and columns to represent and store information. These databases are built on the principles of the relational model, which was first introduced by Edgar F. Codd in 1970. Relational databases are widely used in a variety of applications due to their ability to ensure data consistency and provide powerful querying capabilities. Here are the key details and features of relational databases:
Key Features:
- Structured Data: In a relational database, data is organized into tables, with each table consisting of rows (records) and columns (attributes). This structured approach ensures data integrity and consistency.
- SQL (Structured Query Language): Relational databases are queried using SQL, a standard language for interacting with these databases. SQL provides a simple and effective way to retrieve, manipulate, and manage data.
- Data Integrity: Relational databases enforce data integrity through constraints, foreign keys, and unique indexes, ensuring that data remains accurate and consistent.
- Relationships: Tables in a relational database can be linked through relationships, such as primary keys and foreign keys, to establish connections between related data sets.
- ACID Properties: Relational databases are known for their adherence to the ACID properties (Atomicity, Consistency, Isolation, Durability), ensuring data consistency and reliability, even in the face of system failures.
Use Cases:
- Transaction Processing Systems: Relational databases are commonly used in applications where financial transactions, order processing, and inventory management are crucial, thanks to their ACID compliance.
- Data Warehousing: Enterprises use relational databases to store and analyze large volumes of historical and transactional data in data warehousing solutions.
- Content Management Systems (CMS): Many content management systems, like WordPress and Joomla, use relational databases to store and manage website content and user data.
- Customer Relationship Management (CRM): CRM systems rely on relational databases to maintain customer records and facilitate interactions between businesses and customers.
- Inventory and Supply Chain Management: Relational databases are used in supply chain and inventory management systems to keep track of stock levels, orders, and supplier information.
Advantages:
- Data Integrity: Relational databases excel in maintaining data integrity through constraints and foreign keys.
- Powerful Querying: SQL provides a robust and standardized way to query and manipulate data, allowing for complex and efficient data retrieval.
- ACID Compliance: ACID properties ensure that the database remains consistent, even in high-concurrency environments.
- Data Relationships: Relational databases allow for establishing relationships between data, which is essential for modeling complex systems.
Drawbacks:
- Scalability: While relational databases are excellent for structured data, they can face challenges when dealing with unstructured or semi-structured data and when scaling horizontally.
- Complex Schema Design: The design of the database schema can be complex, especially for applications with intricate data models.
- Performance: In scenarios where read-heavy operations are required, relational databases may need optimization to maintain high performance.
In conclusion, relational databases remain a foundational choice for data storage and management in various applications where data consistency, data integrity, and the ability to model complex relationships are essential. Despite the rise of NoSQL databases for certain use cases, the structured and ACID-compliant nature of relational databases makes them a dependable choice for many industries and systems.
1.1. MySQL
- MySQL is an open-source relational database management system (RDBMS).
- Known for its speed and reliability, it’s widely used in web applications.
- Supports various storage engines, including InnoDB and MyISAM.
MySQL is an open-source relational database management system (RDBMS) that has earned a strong reputation as one of the most popular databases globally. It was originally developed by MySQL AB, and it is now owned and maintained by Oracle Corporation. Here are the key details and features of MySQL:

Key Features:
- Open Source: MySQL is an open-source database system, which means it is freely available for use, modification, and distribution. This open nature has contributed to its widespread adoption and a large user community.
- Ease of Use: MySQL is known for its ease of use and a relatively low learning curve, making it an excellent choice for beginners and small to medium-sized projects.
- High Performance: It is designed for speed and reliability, making it suitable for a wide range of applications, from simple websites to large-scale enterprise systems.
- Scalability: MySQL offers both vertical and horizontal scalability options. Vertical scalability involves upgrading hardware, while horizontal scalability involves adding more servers to distribute the workload.
- Multiple Storage Engines: MySQL supports various storage engines, each with its own set of features and use cases. InnoDB, MyISAM, and MEMORY are some of the commonly used engines. InnoDB is known for its transaction support and data integrity.
- ACID Compliance: MySQL ensures the ACID (Atomicity, Consistency, Isolation, Durability) properties, making it a reliable choice for applications where data consistency and integrity are critical.
Use Cases:
- Web Applications: MySQL is extensively used in web development, powering popular content management systems like WordPress, Drupal, and Joomla.
- E-commerce: Many e-commerce platforms, including Magento and WooCommerce, rely on MySQL for their product and order management.
- Data Warehousing: MySQL can also be used for data warehousing when combined with other tools for reporting and analytics.
- Small to Medium-sized Businesses: Its ease of use, cost-effectiveness, and performance make MySQL a preferred choice for many small and medium-sized businesses.
- Online Forums and Social Networks: Platforms like phpBB and Facebook have used MySQL to handle massive amounts of data efficiently.
Advantages:
- Community Support: MySQL has a vast user community, so finding resources, tutorials, and solutions to common issues is relatively easy.
- Cost-Effective: Being open source, MySQL is cost-effective, especially for startups and small businesses.
- Cross-Platform Compatibility: MySQL runs on various platforms, including Windows, Linux, macOS, and more.
- Customization: MySQL’s extensible nature allows users to customize and optimize the database according to their specific needs.
Drawbacks:
- Limited Features in the Free Version: While MySQL is open source, Oracle offers a commercial version with advanced features, which might be required for specific enterprise use cases.
- Not Ideal for Highly Complex Transactions: While MySQL is suitable for most transactional applications, it might not be the best choice for extremely complex transactions and data manipulation scenarios.
In conclusion, MySQL remains a top choice for database management, particularly for those seeking a reliable, cost-effective, and easily manageable RDBMS solution. Its versatility, performance, and open-source nature have contributed to its enduring popularity among developers and organizations around the world.
1.2. PostgreSQL
- PostgreSQL is a powerful, open-source RDBMS known for its advanced features.
- It excels in complex queries, data integrity, and extensibility.
- Popular in industries where data consistency is paramount, such as finance.
PostgreSQL, often referred to as “Postgres,” is an open-source relational database management system (RDBMS) known for its advanced features, extensibility, and strong emphasis on data integrity. PostgreSQL is developed and maintained by the PostgreSQL Global Development Group, and it has gained a reputation as one of the most powerful and reliable database systems available. Here are the key details and features of PostgreSQL:
Key Features:
- Open Source: PostgreSQL is an open-source database system, which means it is freely available for use, modification, and distribution. Its open nature encourages collaboration and innovation.
- Data Integrity: PostgreSQL places a strong emphasis on data integrity and enforces data consistency through the implementation of constraints, foreign keys, and other mechanisms. This makes it an excellent choice for applications where data accuracy is critical.
- Extensibility: PostgreSQL’s extensibility allows users to define custom data types, operators, functions, and even develop their own extensions to enhance its functionality.
- Advanced SQL Support: PostgreSQL supports a wide range of SQL features, including complex queries, subqueries, and window functions, making it a powerful tool for data analysis and reporting.
- Concurrency Control: PostgreSQL employs multi-version concurrency control (MVCC), allowing multiple transactions to work concurrently without locking conflicts. This ensures high performance in multi-user environments.
- Scalability: PostgreSQL offers various methods for scaling, including table partitioning and built-in replication features. It can handle large datasets and complex workloads.
Use Cases:
- Enterprise Applications: PostgreSQL is commonly used in enterprise-level applications that require robust data handling, such as finance, healthcare, and government systems.
- Geographic Information Systems (GIS): PostgreSQL’s support for spatial data makes it a popular choice for GIS applications, where geographic data and spatial analysis are essential.
- Content Management Systems (CMS): Some popular CMS platforms, like Drupal and Joomla, offer PostgreSQL support as an option.
- Data Warehousing: PostgreSQL is also suitable for data warehousing when combined with other tools for analytics and reporting.
- Scientific Research: PostgreSQL is utilized in scientific research applications due to its support for complex data structures and extensibility.
Advantages:
- Data Integrity: PostgreSQL’s focus on data integrity makes it an ideal choice for applications that require accurate and consistent data.
- Extensibility: The ability to customize and extend PostgreSQL’s functionality allows developers to adapt it to a wide range of use cases.
- Community Support: PostgreSQL has an active and engaged community, providing a wealth of resources and support.
- ACID Compliance: It ensures ACID compliance, which is crucial for applications where data consistency and reliability are paramount.
Drawbacks:
- Learning Curve: PostgreSQL can be more challenging for beginners due to its extensive feature set and complex configuration options.
- Resource Intensive: While PostgreSQL’s performance is robust, it may consume more resources than other RDBMS solutions, which can be a concern for some applications.
In summary, PostgreSQL is a powerful, open-source RDBMS known for its data integrity, extensibility, and advanced SQL support. It is particularly well-suited for applications where data accuracy and complexity are critical, making it a top choice for enterprises, research institutions, and organizations that demand a high level of control over their database operations.
1.3. Microsoft SQL Server
- Developed by Microsoft, SQL Server is a robust RDBMS for Windows environments.
- It offers excellent integration with other Microsoft products.
- Widely used in enterprise-level applications and data warehousing.
Microsoft SQL Server, commonly referred to as SQL Server, is a robust relational database management system (RDBMS) developed by Microsoft. It is known for its seamless integration with other Microsoft products, comprehensive feature set, and its ability to handle large enterprise-level databases. Here are the key details and features of Microsoft SQL Server:
Key Features:
- Enterprise-Grade: SQL Server is designed for enterprise-level applications and provides features and capabilities that meet the high demands of large organizations.
- Tight Integration: Microsoft SQL Server seamlessly integrates with other Microsoft products and services, such as Windows Server, Azure, and .NET Framework. This integration makes it a preferred choice for Windows-centric environments.
- Scalability: SQL Server offers various scalability options, including the ability to manage vast amounts of data and support for horizontal scaling through SQL Server AlwaysOn Availability Groups.
- Security: SQL Server provides robust security features, including encryption, authentication, and authorization mechanisms. It is commonly used in industries with stringent data security requirements, such as finance and healthcare.
- Business Intelligence: It includes integrated support for business intelligence and reporting, with tools like SQL Server Reporting Services (SSRS) and SQL Server Analysis Services (SSAS).
- High Availability: SQL Server offers high-availability features like failover clustering and database mirroring to ensure minimal downtime in critical systems.
Use Cases:
- Enterprise-Level Applications: SQL Server is often the go-to choice for large organizations that require a powerful, scalable database system to handle mission-critical data.
- Business Intelligence and Reporting: Its integration with tools like SSRS and SSAS makes SQL Server a popular choice for data warehousing, analytics, and reporting.
- E-commerce: SQL Server is used in various e-commerce platforms to manage product catalogs, orders, and customer data.
- Windows-Centric Environments: Organizations that rely heavily on Microsoft technologies often opt for SQL Server due to the seamless integration with Windows operating systems.
- Healthcare and Finance: Industries with strict regulatory requirements and data security concerns frequently choose SQL Server for its robust security and compliance features.
Advantages:
- Integration with Microsoft Ecosystem: For organizations that heavily use Microsoft products and services, SQL Server offers a natural and efficient database solution.
- Enterprise-Grade Features: SQL Server provides enterprise-level features for data management, security, and high availability.
- Scalability: It can scale to handle large amounts of data and high workloads, making it suitable for growing organizations.
- Business Intelligence: The built-in support for business intelligence tools simplifies data analysis and reporting.
Drawbacks:
- Cost: SQL Server is not open source, and licensing costs can be substantial, particularly for larger deployments.
- Platform Dependency: Its tight integration with Windows can be a limitation for organizations looking for cross-platform compatibility.
In conclusion, Microsoft SQL Server is a robust and feature-rich RDBMS ideal for enterprise-level applications, especially in Windows-centric environments. Its seamless integration with Microsoft technologies, high availability features, and scalability make it a preferred choice for organizations seeking a powerful database solution for mission-critical data management and business intelligence.
- NoSQL Databases:
NoSQL databases, often referred to as “Not Only SQL” or “non-relational databases,” represent a category of database management systems that diverge from the traditional structured and tabular data model of relational databases. These databases are designed to handle various data types and offer more flexibility, scalability, and performance, making them suitable for modern applications with diverse and evolving data requirements. Here are the key details and features of NoSQL databases:
Key Features:
- Schema Flexibility: NoSQL databases offer schema-less or flexible schema data models, allowing developers to store and query data without requiring a fixed, predefined schema.
- Data Types: NoSQL databases can handle a wide range of data types, including structured, semi-structured, and unstructured data, making them ideal for modern, data-rich applications.
- Horizontal Scalability: NoSQL databases are designed for horizontal scaling, which means they can easily distribute data across multiple servers or nodes, accommodating high traffic and big data workloads.
- High Performance: Many NoSQL databases are optimized for specific use cases, offering fast read and write operations. This makes them suitable for real-time applications.
- NoSQL Models: NoSQL databases are categorized into several models, including document stores, key-value stores, column-family stores, and graph databases, each with its specific use cases and strengths.
Use Cases:
- Big Data: NoSQL databases are often the choice for managing and analyzing large volumes of data, commonly found in big data applications and analytics.
- Real-Time Applications: Systems requiring low-latency and high-throughput, such as gaming, streaming, and social media platforms, often use NoSQL databases for fast data access.
- Content Management: NoSQL databases are used in content management systems (CMS) and e-commerce platforms to manage diverse types of content and product information.
- IoT (Internet of Things): IoT applications generate massive amounts of data, and NoSQL databases can efficiently store and process this data in real time.
- Caching: Key-value stores, like Redis, are widely used for caching data, enhancing the performance of web applications.
Advantages:
- Flexibility: NoSQL databases allow for dynamic and evolving data structures, which is especially advantageous in agile development and fast-changing environments.
- Scalability: Horizontal scaling is a primary advantage, allowing NoSQL databases to handle growing data and user loads without major architectural changes.
- Performance: NoSQL databases are optimized for performance, often providing sub-millisecond response times for read and write operations.
- Diverse Models: NoSQL databases offer various data models, making them versatile for different use cases.
Drawbacks:
- Lack of ACID Compliance: Many NoSQL databases sacrifice full ACID compliance for better performance and scalability, which may not be suitable for applications requiring strict data consistency.
- Complex Querying: Querying in NoSQL databases can be more complex, and ad-hoc querying may not be as straightforward as SQL in relational databases.
- Learning Curve: Developers with a background in relational databases may face a learning curve when adapting to NoSQL databases and their diverse models.
In conclusion, NoSQL databases provide a compelling alternative to traditional relational databases, catering to the demands of modern applications with diverse data types, high scalability needs, and performance requirements. While they may not fit every use case, their flexibility and suitability for big data and real-time applications have made them an essential component of the evolving database landscape.
2.1. MongoDB
- MongoDB is a leading NoSQL database that stores data in flexible, JSON-like documents.
- Ideal for projects with rapidly changing requirements and large data volumes.
- Widely used in content management systems and real-time analytics.
MongoDB is a widely-used NoSQL database that falls into the category of document databases. Developed by MongoDB Inc., it is known for its flexibility, scalability, and the ability to store and manage data in a way that is more representative of how it is used in applications. Here are the key details and features of MongoDB:
Key Features:
- Document-Oriented: MongoDB stores data in JSON-like documents, making it a natural choice for applications where data structures are evolving and flexible.
- Schema-Less: Unlike relational databases, MongoDB does not require a fixed schema. Documents in a collection can have different fields, allowing for easy data model changes.
- Scalability: MongoDB is designed for horizontal scalability. It can distribute data across multiple servers, providing high availability and the ability to handle large amounts of data.
- Powerful Query Language: MongoDB uses a query language that allows for complex queries and supports indexing for efficient data retrieval.
- Geospatial Data Support: It has built-in support for geospatial data and is often used in location-based applications.
- Aggregation Framework: MongoDB includes a powerful aggregation framework for data analysis and transformation.
Use Cases:
- Content Management: MongoDB is commonly used in content management systems, as it can efficiently manage various content types and their associated metadata.
- Real-Time Analytics: Its flexibility and ability to handle unstructured data make MongoDB suitable for real-time analytics and event logging.
- Internet of Things (IoT): IoT applications generate a massive amount of unstructured data, and MongoDB’s scalability and flexibility are well-suited to handle IoT data.
- Catalogs and Product Management: E-commerce platforms often use MongoDB to manage product catalogs and related information, as it allows for changes and updates without altering the entire schema.
- Log and Event Data: MongoDB is used to store log data from various applications, making it easier to analyze and query logs.
Advantages:
- Flexibility: MongoDB’s schema-less approach allows for rapid development and accommodates changing data requirements.
- Scalability: It can easily scale horizontally, making it suitable for applications with growing data needs.
- High Performance: MongoDB offers high read and write performance, making it suitable for real-time applications.
- Geospatial Capabilities: Its native support for geospatial data simplifies location-based applications.
Drawbacks:
- Consistency: MongoDB sacrifices full ACID compliance for scalability and performance, which may not be suitable for applications requiring strict data consistency.
- Complex Queries: Developing complex queries in MongoDB may require a good understanding of the database structure.
- Data Size: MongoDB’s flexibility can lead to data size inconsistencies, as documents may vary in structure.
In conclusion, MongoDB is a versatile NoSQL database that excels in scenarios where data flexibility, scalability, and real-time performance are crucial. Its document-oriented approach and support for unstructured data make it a popular choice for a wide range of modern applications, from content management to IoT and real-time analytics. However, developers should carefully consider their application’s specific needs and data consistency requirements before adopting MongoDB.
2.2. Cassandra
- Apache Cassandra is a highly scalable NoSQL database, designed for high availability.
- It is a favorite for time-series data, sensor data, and IoT applications.
- Used by companies like Netflix and eBay for data management.
Cassandra, named after the Greek mythological figure Cassandra, is a highly scalable and distributed NoSQL database system developed by Apache. It falls under the category of column-family databases and is designed to handle large amounts of data across multiple commodity servers while providing high availability and fault tolerance. Here are the key details and features of Cassandra:
Key Features:
- Distributed and Decentralized: Cassandra is designed to operate across a distributed network of nodes, allowing for linear scalability by adding more servers to the cluster. It follows a decentralized architecture, where there is no single point of failure.
- Column-Family Data Model: Unlike traditional SQL databases, Cassandra uses a column-family data model. It stores data in a way that is optimized for reading and writing large volumes of data, especially time-series data.
- High Availability: Cassandra ensures high availability through its distributed architecture and support for data replication across multiple nodes. It can withstand node failures without data loss.
- Tunable Consistency: Cassandra allows users to define the level of consistency they need for their data, offering options like strong consistency or eventual consistency, depending on the use case.
- Scalability: Cassandra can easily scale horizontally by adding more nodes to the cluster. This makes it suitable for applications with ever-growing data demands.
Use Cases:
- Time-Series Data: Cassandra is an excellent choice for time-series data storage, making it ideal for applications like IoT, sensor data, and event logging.
- Big Data and Real-Time Analytics: Its scalability and high write throughput make it a preferred option for big data and real-time analytics, where large volumes of data are continuously processed.
- Social Media and Messaging: Cassandra is used by social media platforms and messaging applications to handle high traffic loads, user interactions, and data storage.
- Content Management: It can be employed in content management systems where fast data retrieval and high availability are critical.
- Financial Services: Some financial institutions use Cassandra to store transactional data and trade history, ensuring data integrity and high availability.
Advantages:
- Scalability: Cassandra is designed for horizontal scaling, making it suitable for large-scale applications with growing data needs.
- High Availability: Its decentralized architecture ensures data is accessible even in the event of node failures.
- Tunable Consistency: Users can define the level of data consistency based on their specific requirements.
- Column-Family Data Model: Optimized for time-series data, making it an efficient choice for time-based applications.
Drawbacks:
- Complexity: Configuring and managing a Cassandra cluster can be complex, especially for those not familiar with distributed systems.
- Querying Complexity: Cassandra’s query language (CQL) may be less intuitive for those used to SQL, and complex queries may require a significant learning curve.
- Eventual Consistency: While Cassandra offers tunable consistency, ensuring strong consistency may require additional complexity in application design.
In conclusion, Cassandra is a powerful NoSQL database system, particularly well-suited for applications that require high availability, scalability, and efficient handling of time-series data. Its decentralized architecture and ability to distribute data across multiple nodes make it a favored choice for organizations dealing with large volumes of data and demanding real-time performance. However, developers should be prepared to invest time in learning how to properly configure and manage a Cassandra cluster to maximize its benefits.
2.3. Redis
- Redis is an open-source, in-memory data store known for its lightning-fast performance.
- It excels in caching and real-time analytics, with support for various data structures.
- Frequently used in gaming and ad tech applications.
Redis (Remote Dictionary Server) is an in-memory data store that is categorized as a NoSQL database. It is known for its high performance, simplicity, and the ability to handle a variety of data structures. Redis is often used in scenarios that require fast data retrieval and caching, real-time analytics, and data structures for applications. Here are the key details and features of Redis:
Key Features:
- In-Memory Database: Redis stores data in RAM, providing extremely fast read and write operations. This makes it ideal for applications requiring low-latency data access.
- Data Structures: Redis supports various data structures, including strings, lists, sets, hashes, and more. This versatility allows developers to address a wide range of use cases.
- Persistence Options: Redis offers persistence options to save data to disk, ensuring data durability even if the server restarts.
- Replication and High Availability: Redis can be configured for replication, allowing for data redundancy and high availability. It supports master-slave replication and automatic failover.
- Pub/Sub Messaging: Redis includes a publish/subscribe messaging system, making it suitable for building real-time applications and messaging services.
- Lua Scripting: Redis supports Lua scripting, enabling custom logic and manipulation of data within the database.
Use Cases:
- Caching: Redis is often used as a caching layer to store frequently accessed data, reducing the load on the primary data store.
- Real-Time Analytics: Its in-memory nature and support for data structures make Redis a popular choice for real-time analytics and counting applications.
- Session Management: Web applications can use Redis to manage user sessions efficiently, as it can quickly store and retrieve session data.
- Message Queues: Redis can be used as a lightweight message queue for task scheduling and background processing.
- Geospatial Data: Redis offers geospatial indexing, making it suitable for location-based applications.
Advantages:
- Low Latency: Redis’s in-memory storage and data structures result in extremely low-latency data access.
- Versatile Data Structures: It supports a wide range of data structures, allowing for efficient data modeling.
- High Availability: Redis can be configured for replication and failover, ensuring data availability.
- Scalability: It can be used as a distributed cache with clusters for horizontal scalability.
Drawbacks:
- Data Durability: While Redis offers persistence options, it is still primarily an in-memory database, so data durability is not as robust as disk-based databases.
- Memory Usage: Storing data in memory can be memory-intensive and may require careful management.
- Complex Queries: Redis is not suitable for complex queries or ad-hoc data analysis, as it lacks the query capabilities of traditional databases.
In conclusion, Redis is a high-performance in-memory data store that excels in applications where low-latency data access and versatile data structures are critical. Its use cases span from caching and real-time analytics to messaging and session management in web applications. However, developers should be mindful of data durability and carefully manage memory usage when working with Redis.
- Document Databases:
Document databases are a type of NoSQL database that store and manage data in a flexible, semi-structured format, typically using documents. Each document can contain various data types, and the structure of documents can evolve over time. Document databases are suitable for applications with varying and unstructured data requirements, making them a versatile choice for modern web and mobile applications. Here are the key details and features of document databases:
Key Features:
- Schema Flexibility: Document databases allow for schema flexibility, which means data can be stored without a fixed schema. Each document can have different fields, making them ideal for dynamic data structures.
- Documents: Data is stored in documents, typically in JSON or BSON format, which are self-contained units containing data and metadata. Documents are often grouped into collections.
- Rich Queries: Document databases provide powerful querying capabilities, allowing for complex queries and indexing on various fields within documents.
- High Performance: They are optimized for read and write operations, making them well-suited for applications that require fast data access.
- Scalability: Document databases can scale horizontally by distributing data across multiple nodes, ensuring high availability and accommodating large datasets.
Use Cases:
- Content Management Systems (CMS): Document databases are commonly used in CMS platforms to store and manage content, as they allow for easy content updates and flexibility in data structure.
- User Profiles: Social media and e-commerce platforms often employ document databases to manage user profiles, as the user data can vary widely.
- Catalogs and Product Management: E-commerce websites use document databases to manage product catalogs, product information, and inventory.
- Blogs and Articles: Document databases are suitable for storing blog posts, articles, and other content that can have varying structures.
- Catalog Management: They are employed in applications where products or items have attributes that can change over time.
Advantages:
- Schema Flexibility: Document databases accommodate evolving data structures, making them ideal for applications with changing data requirements.
- Rich Queries: They offer powerful querying capabilities, supporting complex and flexible search criteria.
- High Performance: Document databases are optimized for read and write operations, providing low-latency data access.
- Scalability: Horizontal scalability enables them to handle growing data needs and traffic loads.
Drawbacks:
- Complex Queries: Developing complex queries can require a good understanding of the database structure, which may be challenging for some users.
- Data Size Variability: Schema-less design can lead to data size inconsistencies in the database, which may require careful management.
- Resource Intensive: The high read and write performance can be resource-intensive, particularly in memory usage.
In conclusion, document databases are well-suited for applications with dynamic data requirements and unstructured or semi-structured data. Their flexibility in data modeling and rich querying capabilities make them a popular choice for a variety of modern applications, such as content management systems, user profiles, and catalog management systems. However, developers should carefully consider their specific use cases and data requirements before opting for a document database.
3.1. CouchDB
- Apache CouchDB is a document-oriented database, focusing on ease of replication.
- Suitable for decentralized applications and situations where offline access is required.
- Used in healthcare and government systems for data synchronization.
CouchDB is a popular document-oriented NoSQL database developed by the Apache Software Foundation. It is designed for ease of use and simplicity, with a focus on providing robust data replication and scalability. CouchDB is known for its distributed architecture, fault tolerance, and a schema-less design that makes it an excellent choice for applications that require flexible data models. Here are the key details and features of CouchDB:
Key Features:
- Document-Oriented: CouchDB stores data in JSON format as documents, making it flexible and accommodating of evolving data structures.
- Schema-Less: There is no fixed schema in CouchDB. Each document can have different fields, and new fields can be added without altering the existing documents.
- Multi-Version Concurrency Control (MVCC): CouchDB uses MVCC to handle concurrent access and modifications to data, ensuring data consistency.
- Replication: CouchDB is known for its robust data replication capabilities, allowing data to be synchronized across distributed nodes and ensuring high availability and fault tolerance.
- MapReduce Views: It offers a powerful querying mechanism using MapReduce views, allowing for efficient data retrieval and complex queries.
- RESTful API: CouchDB provides a RESTful HTTP API, making it easy to interact with the database using standard HTTP methods.
Use Cases:
- Collaborative Applications: CouchDB is often used in collaborative and distributed applications where multiple users or devices need to access and update data.
- Content Management Systems (CMS): It is suitable for CMS platforms where content is dynamic and can have varying attributes and structures.
- Mobile and Offline Applications: CouchDB’s replication capabilities make it an excellent choice for mobile applications that require offline data access and synchronization.
- IoT Data: In the Internet of Things (IoT) domain, CouchDB can efficiently handle time-series data and device information.
- Offline-First Applications: Applications that need to function effectively in offline scenarios, with data synchronization when online, can benefit from CouchDB.
Advantages:
- Schema Flexibility: CouchDB’s schema-less design allows for agile data modeling and changes to data structure.
- Data Replication: It excels in data replication and synchronization, which is valuable for applications with distributed users or devices.
- Fault Tolerance: CouchDB’s distributed architecture ensures data availability even in the event of node failures.
- MapReduce Views: The querying mechanism offers powerful data analysis and retrieval capabilities.
Drawbacks:
- Complexity of MapReduce Views: Developing and optimizing MapReduce views may require a good understanding of CouchDB’s design, making it a bit complex for beginners.
- Query Performance: Complex queries and large data sets may impact query performance.
- Storage Overhead: The MVCC model can result in storage overhead, especially when many document revisions are kept.
In conclusion, CouchDB is a versatile document-oriented NoSQL database that emphasizes flexibility, data replication, and distributed architecture. It is well-suited for applications where schema flexibility, data synchronization, and fault tolerance are essential, such as collaborative applications, content management systems, and IoT data management. Developers should carefully consider their data requirements and the complexity of queries when choosing CouchDB for their projects.
3.2. Couchbase
- Couchbase is another document database that combines the flexibility of JSON documents with the power of SQL-like querying.
- Well-suited for e-commerce, gaming, and personalized content delivery.
Couchbase is a NoSQL database that combines the flexibility of a document-oriented database with the performance and scalability of a key-value store. It is designed for high performance, high availability, and ease of use, making it a powerful choice for modern applications that require flexibility, speed, and reliability. Here are the key details and features of Couchbase:
Key Features:
- Document-Oriented: Couchbase stores data as JSON documents, which allows for flexible and dynamic data models. Documents are organized into collections.
- Key-Value Store: In addition to the document-oriented capabilities, Couchbase can be used as a key-value store, offering fast data retrieval for simple key-based access.
- Memory-Centric: Couchbase emphasizes in-memory storage for frequently accessed data, leading to low-latency read and write operations.
- Scalability: It is designed for horizontal scalability, with the ability to add nodes to a cluster to handle increased data loads and traffic.
- High Availability: Couchbase provides high availability through data replication and automatic failover, ensuring data is accessible even in case of node failures.
- N1QL Query Language: Couchbase introduces N1QL (pronounced “nickel”), a SQL-like query language that allows for powerful and flexible querying of JSON data.
Use Cases:
- High-Performance Web Applications: Couchbase is often used in applications that require low-latency data access, such as e-commerce websites and real-time applications.
- User Profiles and Personalization: It is suitable for applications that require storing and managing user profiles and personalized data.
- Caching: Couchbase is used as a caching layer for frequently accessed data, reducing the load on primary data stores.
- IoT Data: In the Internet of Things (IoT) domain, Couchbase efficiently manages the large volumes of data generated by connected devices.
- Session Management: Web applications use Couchbase to manage user sessions and session data effectively.
Advantages:
- Flexibility: Couchbase’s document-oriented approach allows for dynamic data modeling and accommodates evolving data structures.
- High Performance: The in-memory storage and key-value capabilities result in low-latency read and write operations.
- Scalability: It can easily scale horizontally to handle growing data needs and traffic loads.
- N1QL Query Language: N1QL provides a SQL-like querying language for powerful and flexible data retrieval.
Drawbacks:
- Complexity: Couchbase’s advanced features may require a learning curve for new users, particularly in setting up and optimizing a cluster.
- Resource Intensive: In-memory storage can be resource-intensive, especially in memory usage.
- Cost: The high performance and advanced features come at a cost, and licensing fees can be substantial.
In conclusion, Couchbase is a versatile NoSQL database that balances the flexibility of document-oriented databases with the speed and scalability of key-value stores. It is an excellent choice for applications that require low-latency data access, high availability, and dynamic data modeling. However, developers should be prepared to invest time in learning the database’s features and complexities, and consider the cost implications of its advanced capabilities.
- Columnar Databases:
Columnar databases, a type of NoSQL database, are designed to store and manage data in a column-wise fashion rather than the traditional row-wise approach used by relational databases. This unique data storage and retrieval structure make columnar databases highly efficient for analytical and reporting purposes, where complex queries and aggregations are common. Here are the key details and features of columnar databases:
Key Features:
- Columnar Storage: Data is stored in columnar databases by column, as opposed to rows, which allows for better data compression and faster query performance for read-heavy operations.
- Analytics Focus: Columnar databases are optimized for analytics, data warehousing, and reporting, making them ideal for applications that require complex data analysis.
- Compression: The columnar structure enables efficient compression techniques, reducing storage requirements and improving query performance.
- Aggregation Support: These databases excel at aggregating data and running complex analytical queries due to their column-wise storage.
- Predominantly Read-Oriented: While columnar databases are highly efficient for read-heavy operations, they may not be the best choice for transactional workloads with frequent write operations.
Use Cases:
- Business Intelligence and Reporting: Columnar databases are commonly used in business intelligence tools, data warehouses, and reporting systems where complex data analysis and ad-hoc querying are prevalent.
- Data Warehousing: Organizations utilize columnar databases for building data warehouses that store vast amounts of historical and transactional data for analysis.
- Financial Analysis: The financial industry employs columnar databases for storing and analyzing financial data, stock market trends, and trading records.
- Healthcare Analytics: In healthcare, columnar databases are used to analyze patient records, medical history, and clinical data for research and reporting.
- Log Analytics: Columnar databases can be suitable for log analytics, helping organizations monitor and analyze system logs and performance data.
Advantages:
- Query Performance: The columnar structure allows for faster query performance, particularly in scenarios requiring complex aggregations and reporting.
- Compression: Efficient data compression techniques result in reduced storage requirements.
- Analytics-Focused: Ideal for analytics, data warehousing, and business intelligence where read-heavy operations are common.
- Schema Flexibility: Many columnar databases offer some level of schema flexibility, which can be advantageous for applications with evolving data models.
Drawbacks:
- Write Performance: Columnar databases may not perform as well with frequent write operations, making them less suitable for transactional workloads.
- Complex Queries: While they excel at complex analytical queries, simple CRUD operations may not be as efficient.
- Learning Curve: Using columnar databases effectively may require a learning curve, particularly for users familiar with traditional row-wise databases.
In conclusion, columnar databases are a specialized class of NoSQL databases optimized for analytics, reporting, and complex data analysis. Their columnar storage structure, compression techniques, and query performance make them a valuable choice for organizations that need to manage and analyze large volumes of data efficiently. However, they may not be the best choice for transactional systems with frequent write operations. Developers should carefully assess their application’s specific needs and data workloads before opting for a columnar database.
4.1. Apache Cassandra
- While known for its NoSQL capabilities, Apache Cassandra also offers column-family storage.
- Ideal for time-series data and analytical workloads.
Apache Cassandra is a distributed NoSQL columnar database management system developed by the Apache Software Foundation. It is designed for high scalability, fault tolerance, and the efficient storage and retrieval of large volumes of data. Cassandra’s architecture is based on the principles of the Dynamo and Bigtable databases, making it a powerful choice for organizations with requirements for distributed and highly available columnar databases. Here are the key details and features of Apache Cassandra:
Key Features:
- Distributed and Decentralized: Cassandra uses a decentralized, peer-to-peer architecture where all nodes are equal. Data is distributed across multiple nodes, making it highly available and fault-tolerant.
- Columnar Storage: Data in Cassandra is stored in a columnar fashion, which is especially efficient for read-heavy workloads and analytical queries.
- Linear Scalability: Cassandra is designed for linear scalability, allowing organizations to add more nodes to the cluster to handle increased data volumes and traffic.
- High Availability: Data in Cassandra is replicated across multiple nodes, ensuring high availability. It can withstand node failures without data loss.
- No Single Point of Failure: Cassandra has no single point of failure, as each node in the cluster can serve as a coordinator for queries and is responsible for a specific range of data.
- CQL (Cassandra Query Language): Cassandra uses CQL, a SQL-like language, for query and data manipulation, making it accessible to those familiar with SQL.
Use Cases:
- Time-Series Data: Cassandra is suitable for applications that involve storing and querying time-series data, such as IoT devices, sensor data, and event logging.
- Log Analytics: It is commonly used for log analytics, providing a scalable platform for analyzing logs from various systems and applications.
- Content Management Systems: Organizations use Cassandra to manage content and metadata, making it accessible for content delivery systems.
- Social Media and Messaging: Social media platforms and messaging applications often rely on Cassandra for its ability to handle high traffic loads and user interactions.
- Financial Services: Some financial institutions employ Cassandra to store and analyze large volumes of financial transaction data.
Advantages:
- Scalability: Cassandra’s linear scalability allows it to handle growing data needs by adding more nodes to the cluster.
- High Availability: The decentralized architecture and data replication ensure high data availability and fault tolerance.
- Columnar Storage: The columnar storage structure is efficient for read-heavy workloads and analytical queries.
- CQL: The use of CQL simplifies the adoption of Cassandra, especially for users familiar with SQL.
Drawbacks:
- Complexity: Setting up and managing a Cassandra cluster can be complex, particularly for those not experienced with distributed systems.
- Query Complexity: Developing and optimizing complex queries in Cassandra may require expertise and experience.
- Storage Overhead: Cassandra’s data replication and columnar storage can result in storage overhead.
In conclusion, Apache Cassandra is a powerful and highly scalable distributed columnar database suitable for applications that require high availability, fault tolerance, and efficient storage and retrieval of data. Its decentralized architecture, efficient columnar storage, and SQL-like query language make it a valuable choice for organizations dealing with large volumes of data. However, developers should be prepared to invest time in learning how to configure and manage a Cassandra cluster effectively.
- Graph Databases:
Graph databases are a type of NoSQL database designed for modeling, storing, and querying data in a graph structure. In a graph database, data is represented as nodes, edges, and properties, which allows for efficient management of complex relationships and interconnected data. Graph databases are particularly suited for scenarios where relationships between data elements are a core aspect of the application. Here are the key details and features of graph databases:
Key Features:
- Graph Data Model: Data in graph databases is represented as nodes, which represent entities, and edges, which represent relationships between entities. Both nodes and edges can have associated properties.
- Relationship-Centric: Graph databases are designed to efficiently manage and traverse relationships, making them ideal for applications with interconnected data.
- Query Language: They often include a graph-specific query language, like Cypher (used in Neo4j), optimized for working with graph data.
- Schema Flexibility: Many graph databases offer schema flexibility, allowing dynamic addition of node and edge types and properties.
- Indexing: Graph databases employ indexing mechanisms to optimize the retrieval of specific nodes and relationships.
Use Cases:
- Social Networks: Graph databases are commonly used in social networking platforms to model and query relationships between users, posts, and other entities.
- Recommendation Engines: They are suitable for recommendation engines, helping to identify patterns and make personalized recommendations based on user behavior and preferences.
- Fraud Detection: Graph databases are used in fraud detection systems to analyze and detect fraudulent activities by identifying suspicious relationships between entities.
- Knowledge Graphs: Organizations use graph databases to build knowledge graphs that represent structured information and relationships between concepts.
- Network and IT Operations: They can help monitor and manage network infrastructure, IT systems, and dependencies.
Advantages:
- Efficient Relationship Handling: Graph databases excel at managing and traversing complex relationships, making them suitable for relationship-centric applications.
- Schema Flexibility: Their schema flexibility is advantageous in scenarios where data models may evolve over time.
- Query Performance: Graph-specific query languages optimize the retrieval of data, making them highly performant for graph-related queries.
- Intuitive Data Modeling: The graph data model intuitively represents entities and relationships, making it easier to map real-world data.
Drawbacks:
- Complexity: While efficient for graph-related queries, graph databases may not be the best choice for simpler data models or non-relationship-centric applications.
- Scalability: Scalability can be a concern for some graph databases, particularly when handling massive datasets or high traffic loads.
- Learning Curve: Developers may need to familiarize themselves with the graph data model and the query language specific to the database they choose.
In conclusion, graph databases are a powerful tool for modeling and querying data with complex and interconnected relationships. They are well-suited for applications where relationships are a central aspect of the data, such as social networks, recommendation engines, and fraud detection systems. While they may not be the best choice for all applications, their efficiency in handling relationships makes them invaluable in scenarios where understanding and leveraging data connections are paramount. Developers should carefully evaluate their application’s data structure and requirements before choosing a graph database.
5.1. Neo4j
- Neo4j is a popular graph database that excels in handling complex relationships.
- Widely used in social networks, recommendation engines, and fraud detection systems.
Neo4j is a widely known and widely used graph database management system. It is designed to efficiently store, manage, and query data in graph structures, making it a powerful tool for applications that heavily rely on relationships between data points. Neo4j is known for its high performance, scalability, and user-friendly query language, Cypher. Here are the key details and features of Neo4j:
Key Features:
- Graph Data Model: Neo4j is based on the property graph model, where data is represented as nodes, relationships, and properties. This model is highly intuitive and efficient for handling interconnected data.
- Cypher Query Language: Neo4j uses Cypher, a graph-specific query language, which allows for expressive and efficient querying of graph data. It simplifies working with complex relationships.
- ACID Compliance: Neo4j is ACID-compliant, ensuring data consistency and reliability even in the presence of concurrent access.
- High Performance: Neo4j is optimized for graph-based queries and can efficiently handle complex traversals and pattern matching.
- Scalability: It supports horizontal scalability through clustering and replication, making it suitable for handling large datasets and high traffic loads.
- Schema Flexibility: Neo4j offers schema flexibility, allowing dynamic addition of node and relationship types and properties.
Use Cases:
- Social Networks: Neo4j is widely used in social networking platforms to model and query relationships between users, their connections, and shared content.
- Recommendation Engines: It is suitable for recommendation engines, providing efficient mechanisms to analyze user preferences and suggest relevant content.
- Fraud Detection: Neo4j is used in fraud detection systems to identify suspicious patterns and relationships between entities or transactions.
- Knowledge Graphs: Organizations build knowledge graphs using Neo4j to represent structured information and the relationships between concepts.
- Network and IT Operations: It helps monitor and manage network infrastructure, IT systems, and dependencies by modeling complex relationships.
Advantages:
- Graph Data Model: Neo4j’s native graph data model is highly intuitive and efficient for representing complex relationships.
- Cypher Query Language: Cypher simplifies the querying of graph data, making it accessible to developers familiar with SQL.
- High Performance: Neo4j excels at graph-based queries, providing fast and efficient traversal and pattern matching capabilities.
- Scalability: It can be scaled horizontally to accommodate large datasets and growing traffic loads.
- ACID Compliance: Neo4j ensures data consistency and reliability.
Drawbacks:
- Complexity: While efficient for graph-related queries, Neo4j may not be the best choice for simpler data models or non-relationship-centric applications.
- Resource Intensive: Storing and managing large graphs can be resource-intensive, particularly in memory usage.
- Learning Curve: Developers may need to learn the graph data model and Cypher query language, which might have a learning curve.
In conclusion, Neo4j is a leading graph database that is highly suitable for applications where relationships are a fundamental aspect of the data, such as social networks, recommendation engines, and fraud detection systems. Its graph data model, Cypher query language, high performance, and ACID compliance make it a valuable tool for efficiently handling complex relationships and interconnected data. Developers should assess their application’s data structure and requirements before choosing Neo4j.
Conclusion
The world of databases is diverse, and the choice of which one to use depends on your specific project requirements. Whether you need a robust relational database for transactional data, a flexible NoSQL database for unstructured information, or a graph database for relationship-heavy applications, there is a solution for you.
It’s important to consider factors like scalability, data model, consistency, and performance when selecting a database system. With the right choice, you can ensure efficient data storage, retrieval, and analysis for your applications, ultimately contributing to their success in today’s data-driven world.
People Also Ask:
Q1: What is a database? A1: A database is a structured collection of data organized for efficient storage, retrieval, and management. It serves as a central repository for storing and managing various types of data.
Q2: What is the difference between SQL and NoSQL databases? A2: SQL databases, or relational databases, use a structured schema and are best suited for well-defined data with complex relationships. NoSQL databases are more flexible, designed for unstructured or semi-structured data, and excel in scenarios requiring high scalability and performance.
Q3: What are the most popular SQL databases? A3: Some of the most popular SQL databases include MySQL, PostgreSQL, and Microsoft SQL Server. These databases are widely used in various applications and industries.
Q4: What are the key features of MySQL? A4: MySQL is known for its open-source nature, ease of use, speed, reliability, and support for various storage engines. It is often used in web applications, content management systems, and e-commerce platforms.
Q5: What are the primary use cases for PostgreSQL? A5: PostgreSQL is highly versatile and is used for a wide range of applications, including web and mobile applications, data warehousing, geographic information systems, and more. It is valued for its extensibility and support for complex data types.
Q6: What is Microsoft SQL Server known for? A6: Microsoft SQL Server is recognized for its integration with Microsoft’s ecosystem, high performance, scalability, and robust security features. It is commonly used in enterprise-level applications, including business intelligence and data warehousing.
Q7: What are NoSQL databases, and when are they used? A7: NoSQL databases are designed to handle unstructured or semi-structured data, providing flexibility, scalability, and high performance. They are used in applications such as real-time analytics, IoT, content management, and more.
Q8: What are the key features of MongoDB? A8: MongoDB is a document-oriented NoSQL database known for its flexible, schema-less design, scalability, high performance, and support for geospatial data. It is used in content management, real-time analytics, IoT, and other applications.
Q9: What is Cassandra’s strength? A9: Apache Cassandra is renowned for its distributed and decentralized architecture, column-family data model, high availability, and scalability. It is commonly used in time-series data, real-time analytics, and IoT applications.
Q10: What is the primary use of Redis? A10: Redis is an in-memory data store often used for caching frequently accessed data, real-time analytics, session management, and message queues.
Q11: What are document databases, and what are their advantages? A11: Document databases are NoSQL databases that store data in flexible, document-like structures. Their advantages include schema flexibility, efficient data modeling, and high read and write performance.
Q12: What are the key features of CouchDB? A12: CouchDB is known for its document-oriented design, schema-less structure, multi-version concurrency control (MVCC), data replication, and RESTful API. It is commonly used in collaborative applications, content management systems, and mobile applications.
Q13: What makes Couchbase stand out? A13: Couchbase combines the flexibility of document databases with the performance of key-value stores. It offers in-memory storage, scalability, and support for efficient data replication. Couchbase is suitable for real-time applications, content management, and session management.
Q14: What are columnar databases, and when are they useful? A14: Columnar databases are designed for efficient storage and retrieval of data in a column-wise fashion, making them ideal for analytical and reporting purposes. They are useful in scenarios with read-heavy operations and complex queries.
Q15: What are the key features of Apache Cassandra? A15: Apache Cassandra is recognized for its distributed and decentralized architecture, column-family data model, high availability, linear scalability, and tunable consistency. It is commonly used in time-series data, real-time analytics, and log data storage.
Q16: What are graph databases, and what are their advantages? A16: Graph databases are NoSQL databases designed to represent data as nodes, edges, and properties, making them highly efficient for modeling and querying interconnected data. Their advantages include efficient relationship handling, schema flexibility, and expressive querying capabilities.
Q17: What is the primary use of Neo4j? A17: Neo4j is a leading graph database known for its efficient relationship management. It is widely used in social networks, recommendation engines, fraud detection, and knowledge graph applications.